
Project Astra: Stateful Lessons for a Multi-Cloud World

Eric Han
 We launched Project Astra at the end of April because it was obvious to us that running stateful applications in Kubernetes is still too difficult for many users.
We launched Project Astra at the end of April because it was obvious to us that running stateful applications in Kubernetes is still too difficult for many users.
The technology promise of Kubernetes lies in changing how applications and providing portability. Meanwhile from business perspective, IT teams have been moving to models that deliver on-premises and in the cloud, typically in an as-a-service model. Project Astra seeks to extend that Kubernetes technology promise to stateful workloads and enable IT to deliver easy to consume storage for Kubernetes in a multi-cloud, as-a-service world.
With the larger Kubernetes community coming together at the first virtual KubeCon Europe, we wanted to share some lessons learned from our early access program, how stateful workloads fit in their multi-cloud world, and also our own lessons building for Kubernetes - while relying on it ourselves.
These lessons, which we’ve learned alongside a group of early access participants made up of the world’s leading companies in digital entertainment, biopharmaceuticals, online media and other demanding industries, are shaping our roadmap for the beta launch of Project Astra in the coming months.
Kubernetes Storage and the Missing User Experience
Our early access users had one common interest that drew them to Project Astra: how to run a full set of workloads in Kubernetes where the right storage is always selected, the performance is managed, and application data is protected.During our first early access program, we enabled Project Astra to manage data for clusters in Google Kubernetes Engine (GKE), where we tuned the Cloud Volume Service (CVS) in Google for the needs of Kubernetes. Our first simple test was whether a Kubernetes administrator could always get the right storage provisioned by use case. As a start, we focused on read-write file workloads, scale-out datastores, and relational databases.
Taking it one step further, we wanted Kubernetes administrators to experience unified app-data management in terms of backup and portability.
To illustrate our first view of portability, we had users try our cloning experience that moves applications and storage from one Kubernetes cluster to another. Through cloning, we imagine a set of multi-cluster, hybrid, and multi-cloud workflows. That being said, an even more basic use case for cloning is moving workloads through a CI/CD pipeline and across Kubernetes namespaces.
The early access release provided a glimpse for cloning that looks like:
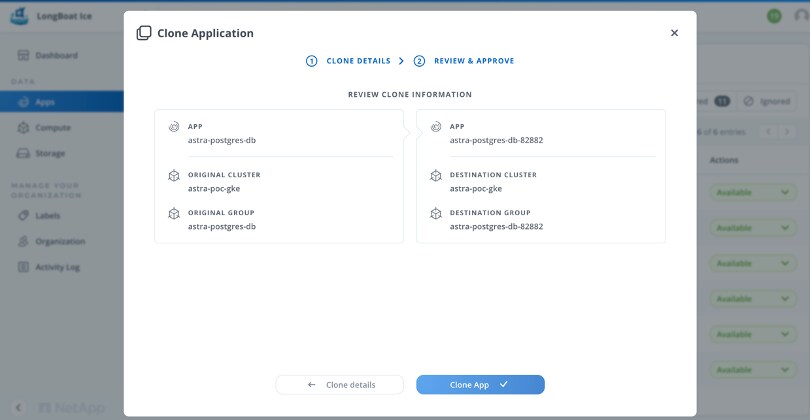 Feedback from end users ranged from sharing which Kubernetes objects should be cloned per use case to the need for consistent cloning for applications with ephemeral volumes. Beyond this “more is better” feedback, one feature that reflects how Kubernetes is becoming mainstream is the request for logging. Simply put, how do we verify and prove who accessed an application’s data?
Feedback from end users ranged from sharing which Kubernetes objects should be cloned per use case to the need for consistent cloning for applications with ephemeral volumes. Beyond this “more is better” feedback, one feature that reflects how Kubernetes is becoming mainstream is the request for logging. Simply put, how do we verify and prove who accessed an application’s data?
As we continued through our releases, we added logs that start to showcase how control and visibility might evolve as app-data becomes a first-class citizen. We look forward to working on how this aspect of control evolves as Kubernetes runs persistent workloads.

Application Selection and Extensions: What Could go Wrong?
As we spent more time with our early access users and their teams, we wanted to understand what applications they were prioritizing for Kubernetes storage and ultimately what is accelerating or inhibiting adoption of those applications in Kubernetes. While this simple set of questions focused on users’ pain points, the broader takeaway became considerations for how we as an ecosystem might collaborate-- as more and more of us leverage extensibility patterns in Kubernetes.Acknowledging that our users were building new, the consistent perspective is that IT teams need a generalized way to manage applications, and managing multiple toolchains for new applications is a non-starter. The more challenging aspect of tools, application choice, and extensibility becomes the priority.
As more technologies extend Kubernetes through mechanisms like Custom Resources and Operators, the ability to manage portability of Customer Resource was a consistent point of feedback. At the same time, we have seen how these extensions can follow very different patterns that impact the data lifecycle. Accordingly, a concrete learning is the need for Project Astra to work with application ISVs writing extensions in the form of Operators.
This is an area we expect to update more as we continue through our feedback cycles. Optimistically, it’s important to acknowledge that this extension proliferation shows the demand for building on Kubernetes, and we believe that this ecosystem can rally to solve it together.
In terms of the commonly requested applications, one ranking experiment with select users showed us a preference for scale-out datastores like MongoDB, Kafka, and Cassandra. At the same time, CI/CD in the form of Jenkins and GitLab and relational databases were important.
The following shows such a ranking experiment for a team of users:
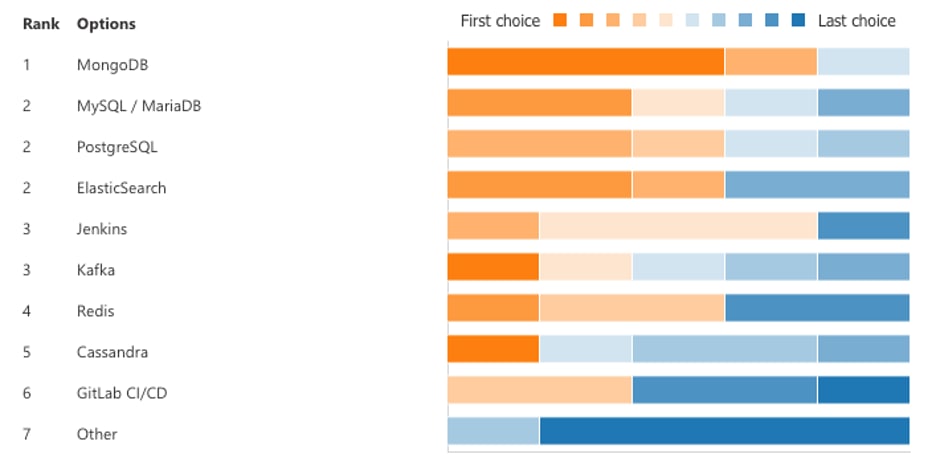 As we delved more into interviews with participants, we started to see domain-specific workloads like genomics, rendering, and other applications specific to an industry. From a ranking perspective, we suspect these domain-specific workloads are equally important, and in an early access testing, teams and our processes might have tended to speak about more common applications. Accordingly, we expect to see more of an application sprawl as we continue our early access programs.
As we delved more into interviews with participants, we started to see domain-specific workloads like genomics, rendering, and other applications specific to an industry. From a ranking perspective, we suspect these domain-specific workloads are equally important, and in an early access testing, teams and our processes might have tended to speak about more common applications. Accordingly, we expect to see more of an application sprawl as we continue our early access programs.
Multi-cluster and Hybrid Workflows that Really Work
With our larger enterprise customers in the early access program, deploying into multiple clouds and on-premises became an important requirement. Thus, as we continue with Project Astra, we are working to accelerate our next release into Azure to support AKS and Kubernetes in AWS with EKS.Equally important, we have been shaping our on-premises release of Astra based on customer feedback. The clear ask from hybrid customers became, “how do we run on-premises stateful Kubernetes with a consistent experience for what we are validating in public clouds?”
As our on-premises release shapes up, we have seen the benefits of streamlining our product development to leverage Kubernetes as the control-plane. To provide some background, managing Kubernetes data has been a multi-year journey that started in the cloud for NetApp. In AWS, Google Cloud, and Azure, the Cloud Volume Service (CVS) provides storage to virtual machines. So, as part of that evolution, the Project Astra team has been redesigning the NetApp storage operating system, ONTAP, to be Kubernetes-native.
This containerized ONTAP now powers some of the key regions in the public cloud, where customers see a VM volume that happens to be backed by a microservice architecture. And as our cloud Project Astra customers ask for on-premises Kubernetes storage, we see the benefits of having our own common control-plane in Kubernetes in that customers can more easily have a consistent app-data experience through Astra whether they are on-prem or in the cloud.
What’s Next?
In our early access release of Project Astra, we wanted to demonstrate a view for how Kubernetes storage could become simple to consume by unifying app-data management and making the experience Kubernetes-native. The feedback has helped us understand how users really want a common set of tools that work for stateless and stateful applications, for built-in Kubernetes objects and extensions, and that run seamlessly in clouds and on-premises.We are encouraged by the appetite for adopting more in Kubernetes and have seen for ourselves the benefits of converging on a common, powerful control-plane.
And finally, we would be remiss if we didn’t conclude with how Kubernetes is changing the world for all applications. The more we invest in this ecosystem, the more we see benefits broaden to new sets of use cases and end users.
One area we would welcome more vendor collaboration on is on how we might shape our Extensions & Operator story together. We think that having a deeper discussion to provide consistency would help and look forward to updating our views here in the new future.
While this first preview release was limited, we look forward to our upcoming public preview of Project Astra. For more information or to sign-up for that free program, you can find us here.
We hope everyone has a great KubeConEU, is staying / feeling safe, and stays in touch!
Thanks, @radio_eric
Eric Han
Eric Han is a VP of CDS Product Management for NetApp’s cloud portfolio. Prior to NetApp, he ran product management at a container-native storage company. Eric started his container journey as the founding product manager for Kubernetes at Google, where he also co-founded Google Kubernetes Engine (GKE) service. Eric began his career at Microsoft in the product teams for Windows Server and Zune music.