Advancing data mobility, data protection and developer efficiency for generative AI applications

Share this page

Puneet Dhawan
In July 2024, we launched NetApp® BlueXP™ workload factory for generative AI, a service from NetApp to help customers accelerate generative AI application development using their company’s private data through the retrieval-augmented generation (RAG) framework. In response to customer and partner input, a key design tenet we’ve followed is to avoid reinventing the wheel when it comes to managing data for generative AI. Rather than creating new data silos and management mechanisms, our customers want to integrate their existing data and extend current methods of managing, securing, and protecting enterprise data for use by generative AI applications. Deployed and managed through workload factory, knowledge bases form the fundamental infrastructure to build generative AI applications and securely connect Amazon Bedrock to private data on NetApp ONTAP® software. Workload factory uses Amazon FSx for NetApp ONTAP as the storage layer for the knowledge bases. Today, we’re pleased to announce that customers can extend NetApp SnapMirror® replication to integrate on-premises data with knowledge bases and improve developer efficiency and data protection by using NetApp Snapshot™ copies of ONTAP volumes to create point-in-time copies of knowledge bases.
Example: Developing a virtual assistant
To illustrate the value of these enhancements, let’s take an example scenario. Consider a life sciences company that wants to cut down their research project times by providing their staff a virtual assistant to help them answer questions based on the company’s corpus of data, including clinical trial results, research literature, regulatory reports, and so on. The research teams are distributed across geographies, the data is stored closer to users in local data centers using NetApp storage, and strict access controls secure access to the company’s confidential information. Although the company does have an in-house application development arm, they don’t have deep expertise in generative AI technologies. Like any other enterprise application in their environment, the virtual assistant must meet the company’s data governance, protection, and regulatory guidelines. Using AWS services such as Bedrock to fast-track development is attractive to their development team because they don’t have to deal with the complexity of deploying and managing the infrastructure needed for language and embedding models. However, to use Bedrock with their research data, they must move data from multiple locations to Amazon S3, synchronize any changes to source data with Amazon S3, configure Identity and Access Management (IAM) policies for user access control, and adopt new mechanisms to protect vector embeddings that will be created as part of the virtual assistant application.
Bringing on-premises data closer to foundation models in AWS
Our example company wants to use Amazon Bedrock to develop their virtual assistant with responses derived from their private research data. As illustrated in Figure 1, NetApp SnapMirror or NetApp FlexCache® software can be used to bring the company’s data from distributed sites closer to the foundation models that are available through Bedrock.
In the latest release of workload factory, we’re making it easier to integrate on-premises data into knowledge bases. Using workload factory, you can set up SnapMirror relationships between on-premises volumes and FSx for ONTAP. These mirrored volumes appear as read-only data protection volumes within FSx for ONTAP (Figure 2). With a few clicks, you can connect a data source (SMB or an NFS share) on a data protection volume and ingest data replicated from on-premises volumes into the knowledge base. If the knowledge base needs to be connected to data sources from multiple sites, multiple data protection volumes can be connected to the same knowledge base. By default, the knowledge bases are refreshed once a day for any changes to the data on source volumes, and data can also be refreshed any time on demand.
Using on-premises NetApp arrays, FSx for ONTAP in AWS, and BlueXP workload factory, this company can avoid the challenges of complexity of integrating on-premises data with Amazon Bedrock. Let’s dive into how to accomplish these goals.
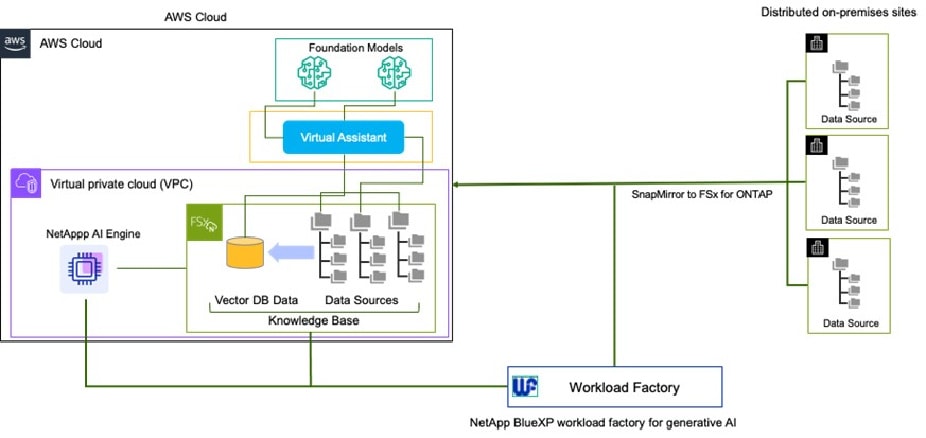
Figure 1) Hybrid RAG architecture with BlueXP workload factory.
Using on-premises NetApp arrays, FSx for ONTAP in AWS, and BlueXP workload factory, this company can avoid the challenges of complexity of integrating on-premises data with Amazon Bedrock. Let’s dive into how to accomplish these goals.

Figure 2) Integrate on-premises data source with a knowledge base.
A lot of our customers already replicate on-premises data to FSx for ONTAP for backup or disaster recovery use cases. The mirrored copies however are not used except when needed for restores. They can now extend the use of these dormant backup copies to build generative AI applications.
Improving security by preserving access control
If data is moved from file shares to Amazon S3, one needs to reconfigure data access as well as integrate access policies into the virtual assistant application. Why deal with extra complexity if you can extend file access policies to the knowledge base? When ingesting data into knowledge bases, workload factory also ingests the file access control list (ACL) configuration for data residing on SMB shares. Developers can then enable authentication on knowledge bases: First, a user is authenticated, and then their configured file access controls settings are used to filter query responses based on the documents that the user has access to. This way, the foundation model cannot augment its responses with data that the user should not be able to access, thereby improving security without increasing the complexity of managing user authentication and data access controls.
Enhancing developer efficiency
When developing, testing or troubleshooting generative AI applications, developers might need to work with views of the knowledge base data at different points in time. For example, a developer might want to change the chunking strategy, ingest documents, test how the change affects the retrieval search results and roll back to a point in time if a change did not yield any benefit. Typically rolling back data to a point in time would involve ingesting the data again or recovering from a backup, both of which hinder test and development velocity. With knowledge base snapshot copies, a developer could use workload factory knowledge base APIs to almost instantaneously create an on-demand point in time copy before making any changes to knowledge base configuration or its data and simply roll back the whole knowledge base to a desired state if needed. This way, developers at our example company can quickly test or troubleshoot different scenarios where they need to work with point in time states of the knowledge base.
Improving data protection
Protecting data infrastructure against accidental data loss, data corruption, or malicious attacks is critical for production-grade generative AI applications. For generative AI applications using the RAG framework, it’s important to consider how you’re protecting the source data, how the data stored in vector databases was embedded, what configuration settings and authentication mechanisms exist, and so on. Designing a data protection strategy that encompasses the whole RAG data infrastructure ensures that you’re protecting the key components and can quickly and easily restore the application data when needed.
With workload factory, you can now easily protect knowledge bases by using ONTAP Snapshot copies. Snapshot copies are near-instantaneous point-in-time copies of the data. If data is lost or corrupted, you can quickly go to a known good point-in-time copy and restore the knowledge base within minutes. While creating a knowledge base, you can attach a Snapshot policy configured on the FSx for ONTAP file system to schedule automatic Snapshot copies (Figure 3), and you can also create Snapshot copies on demand.
The storage or platform administrators at our example company can set up automated knowledge base Snapshot copies so that data is protected to meet their SLAs. To recover, they can select a point-in-time Snapshot copy and—within minutes—restore the knowledge base to the desired good known state.
Each knowledge base uses a separate volume on FSx for ONTAP, which stores both the knowledge base data and the knowledge base configuration. Upon restore, the underlying volume is restored to its point-in-time version, and workload factory restores the knowledge base to its point-in-time configuration.

Figure 3) Attaching a Snapshot policy to a knowledge base.
Getting started
We’re excited to bring these new enhancements to knowledge bases managed through BlueXP workload factory. We’re constantly working to help our customers use their data for generative AI applications in a simple, secure, and cost-effective manner; stay tuned for lots more to come!
Watch our overview video to learn more and to get started, sign up with BlueXP workload factory.
Puneet Dhawan
Puneet is a Senior Director of Product Management at NetApp where he leads product management for FSx for NetApp ONTAP service offering with AWS with specific focus on AI and Generative AI solutions. Before joining NetApp, Puneet held multiple product leadership roles at Amazon Web Services (AWS) and Dell Technologies in areas of hybrid cloud infrastructure, cloud storage, scale-out and distributed systems, high performance computing and enterprise solutions, etc. In those roles he led product vision and strategy, roadmap planning and execution, partnerships, and go-to-market strategy.